

Hopefully, you caught our blog post about onboarding automation using artificial intelligence and machine learning. This follow-on blog shows an example using machine learning to predict the onboarding risk for a particular applicant, but takes that a step further by replacing a previously manual (human) task with a completely automated task instead.
Camunda’s composable architecture allows you to streamline your processes by easily swapping out manual components with their automated counterparts with ease.
Manual risk verification
In this example using a manual risk verification, let’s assume we have a Camunda process already in place. We’re going to review loan applicants by checking their credit scores and other financial information to help determine an initial risk value. This will help determine if the loan should be offered.
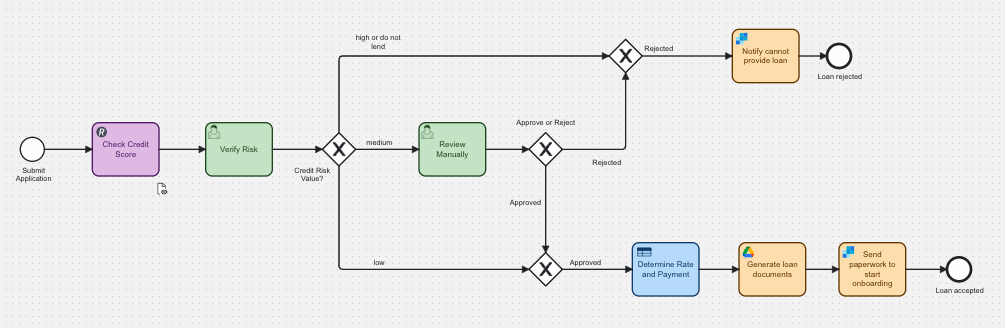
This process makes a call to a service to obtain certain relevant financial information about the applicant that is then used to help determine the loan risk. However, the prediction of risk is done using a program that does not have an API for making a call. Instead, the loan officer must manually enter information (copy/paste) into another program to obtain the risk.
Based on the results of that legacy system access, the loan decision will be given one of these statuses:
- Rejected: For loans that have “high” or “do not lend” for the loan risk.
- Approved: For loans that have a “low” risk.
- Manual review: For loan applications that have “medium” risk; a loan supervisor will review all the information to make the final decision on the loan application.
As you can imagine, this existing process relies on humans at both the risk determination and the manual verification stage, which can slow down a process. But even more important, this human task can cause errors and limit your ability to audit your process effectively. With a “disconnect” or a loan officer running an application outside of your loan onboarding process, you lose visibility into the process which can affect compliance.
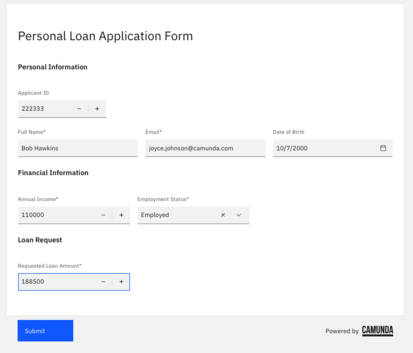
Let’s take a look at this process when executed. First, fill out the Personal Application Form requesting the loan.
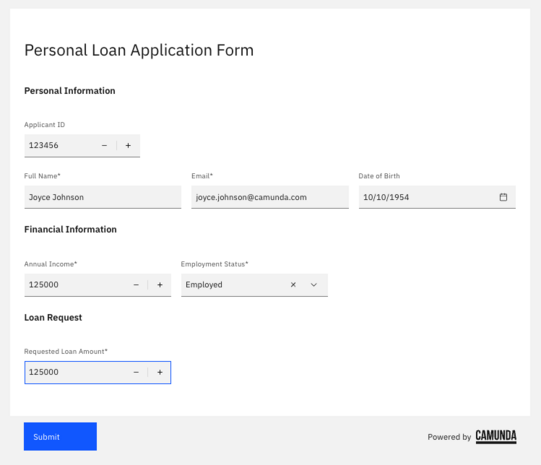
Once the application is submitted, the process runs a check to return the credit score and other pertinent financial information for the applicant.
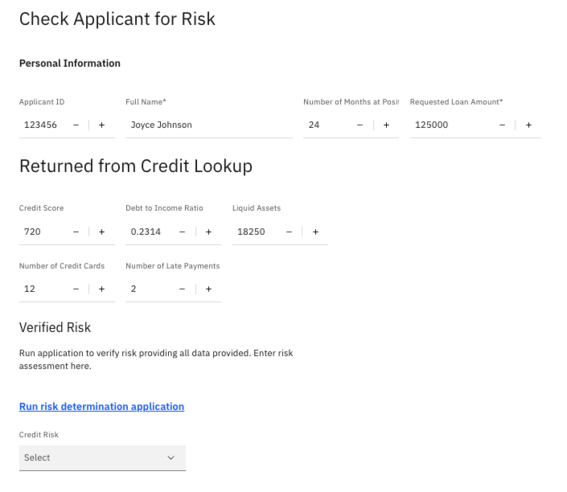
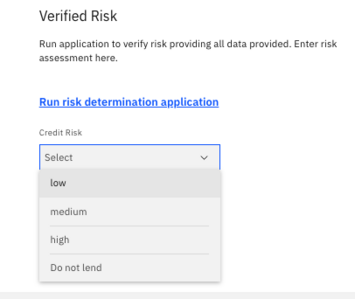
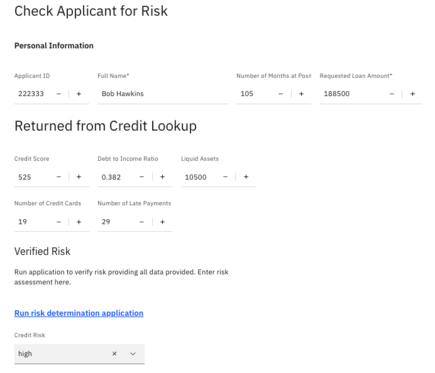
This information is presented to a loan officer, who must review it and then access the risk determination application to predict the risk for this applicant.
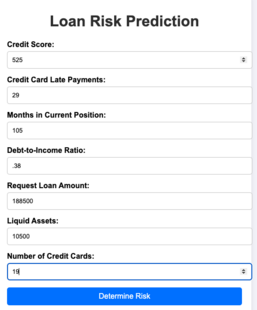
Note: The risk determination application is written in Python and uses past applicant data as the training data to enhance and refine our risk prediction accuracy. The code accepts the data shown in the next figure to make this determination.
This entails copying the data provided to another application.
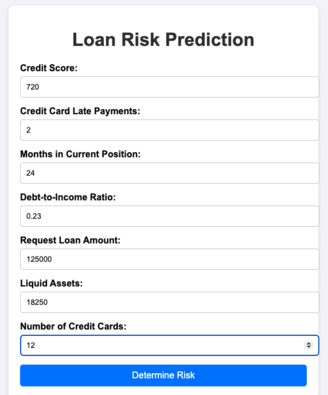
The application returns a risk determination.

Then the loan officer updates the form with the risk to continue the process.
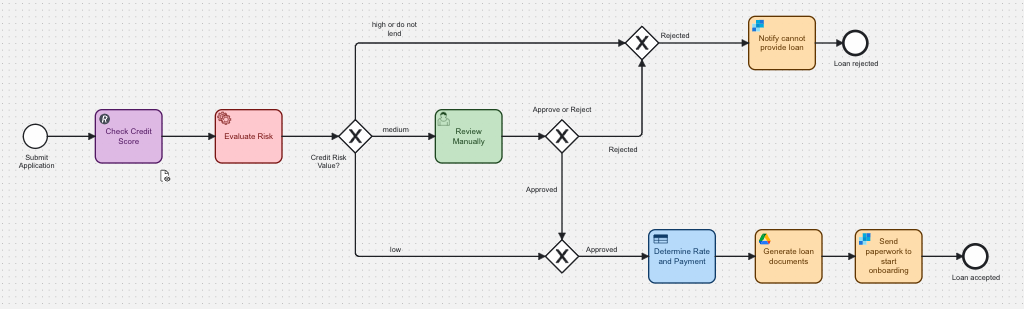
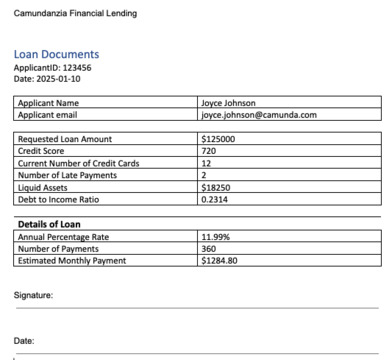
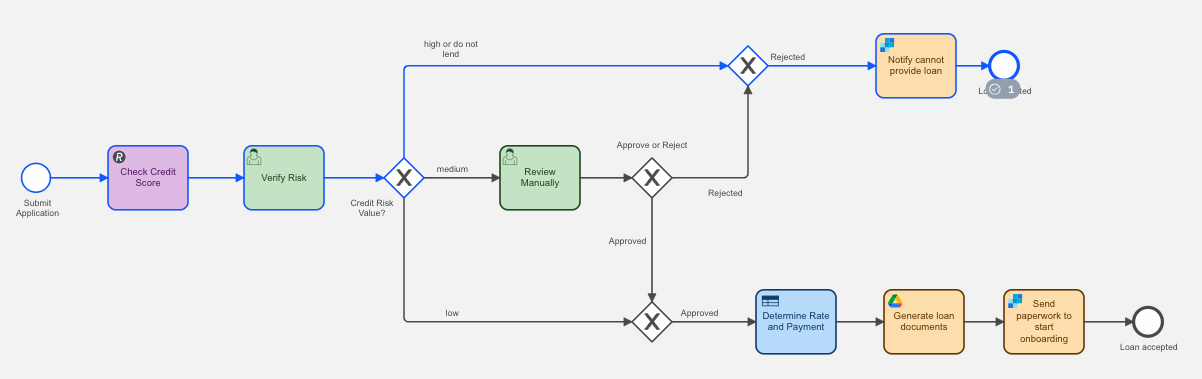
In this situation, the process determines that the risk for lending to this applicant is low. The process generates the loan documents and makes them available to the applicant as per the associated email. The diagram below shows the branches taken in this case.
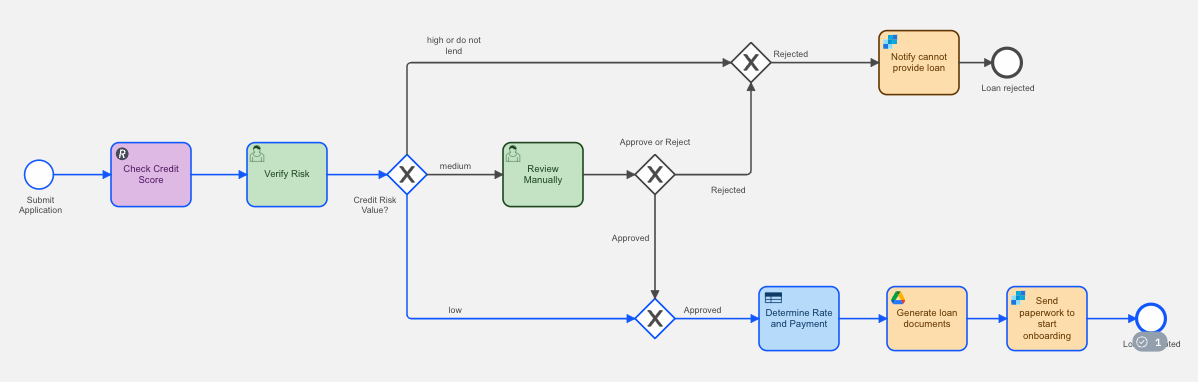
The applicant receives an email with a link to the loan documentation.
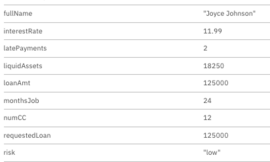
The information in the documentation is calculated using the interest rates determined by the financial information for that applicant. In this case, the rate is 11.99% with an estimated monthly payment of $1,284.80 each month for 30 years.

We can see the path taken by the applicant with Camunda Operate, as well as inspect the variables of the process.
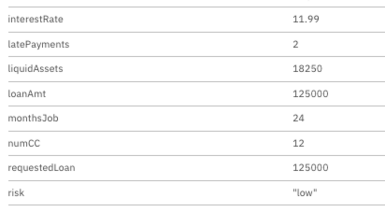
The value for the risk for this particular applicant is shown in the risk variable in the process. Although this process works well and takes advantage of connectors and decision management and notation (DMN) for decision-making, it does have a human step that takes context out of the process. This leaves room for error and less auditability and visibility.
Possible issues
Let’s assume that the loan officer transposes the number of late payments with the time in the current position as indicated below.


This will indicate that the applicant is at “medium” risk, not the “low” risk which is correct. Take that a step further and assume the loan officer incorrectly input the credit score for the applicant in addition to the switch between credit card late payments and time in the current position.
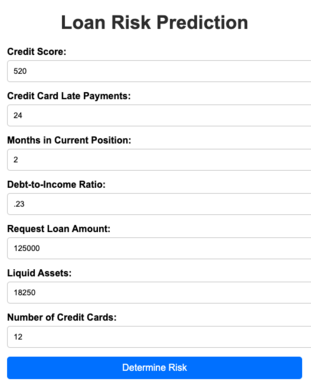

This would automatically reject the applicant for the loan.
Unfortunately, since the data in the process is correct for each of these parameters, we have no visibility into what might have happened when the loan officer input the data into the loan risk prediction application and what results that caused. There is no auditability into what went wrong, which can be devastating to our potential and existing clients and customer loyalty.
This lack of governance and visibility into your process can lead to regulation and compliance issues. We will now take a look at the difference in a process when this is replaced with an automated task to provide end-to-end visibility.
Replace manual risk verification with automation
Let’s assume that my organization has developed a script that will allow Camunda to run our prediction application programmatically. It should minimize human error, streamline the process, and provide visibility into all aspects involved in onboarding decision-making.
With Camunda’s composable architecture, it is quite simple to swap or replace a human step with a connector or other automated functionality—in this case a service task—in order to achieve these enhancements.
Let’s look at how that can be done.
Anatomy of the service task
In this case, our development team has created a JavaScript program that spawns our Python prediction algorithm for determining the risk for the applicant. Using this code, we can execute the Python application from the Camunda process using a service task instead of waiting on an available human who may or may not incorrectly input the data.
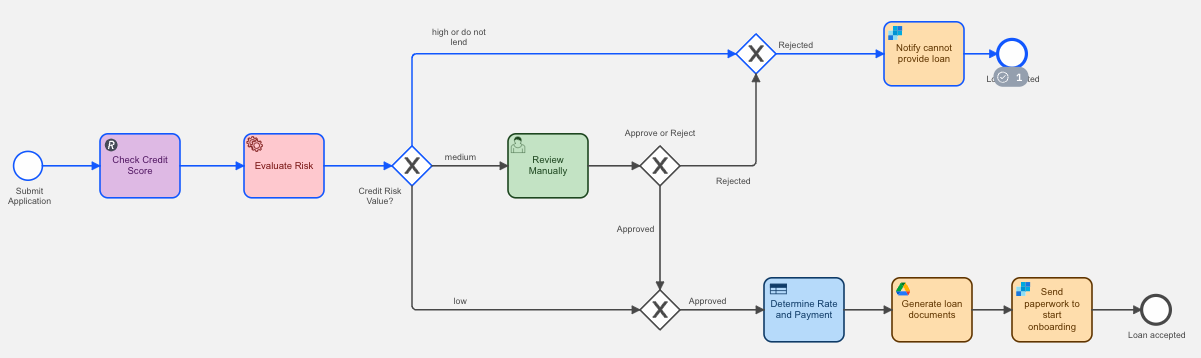
In order to accomplish this task, we alter the process to replace the Verify Risk human task with a service task (in red) as shown below.
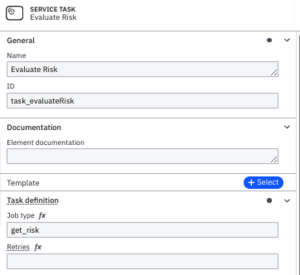
For the service task, we make sure that we have imported the required Zeebe variables, and then create our job worker that subscribes to our job type by referencing it in the process. This service will wait for jobs that reference the task type and then run the code which calls our Python prediction model.
Swapping out the manual task
Essentially, the process looks much the same after swapping the human task with the service task; we simply gain end-to-end visibility into the process. The service task code needs to be running waiting to execute when the task is called from the process.
Let’s see how this would look at execution and what we gain from taking this approach. We start with the same form without any changes. This again, reinforces the beauty of composability, as we do not need to change our form to support the element change to a service task.
Without the need to wait for an available loan officer, this process quickly obtains the credit score and other financial information and moves to verify the risk. For this example, we have the service task writing a log so that you can see what is happening in the Verify Risk task.

Here you see that the function has been called (and some of the variables from the process) and the result of a “low” credit risk from the program.
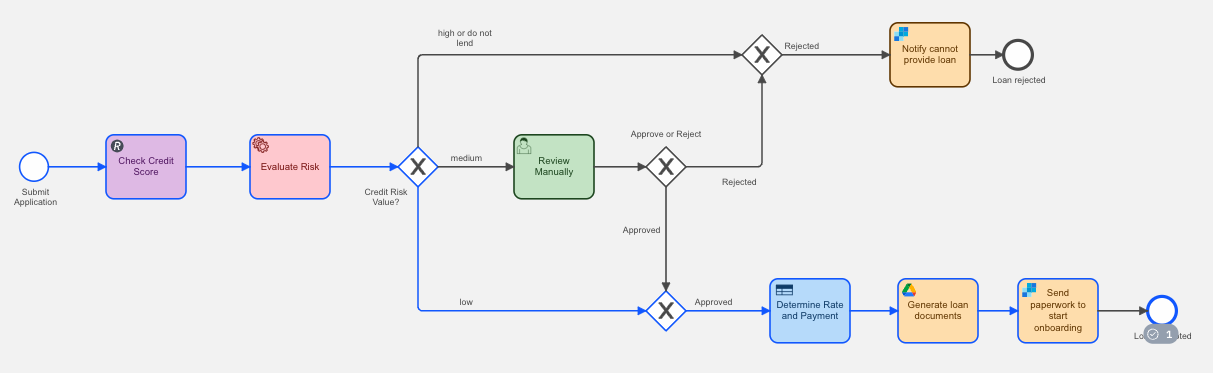
The same branch is taken to approve the loan without human intervention and create the appropriate loan documentation for the applicant to sign.
Streamlining your process
Although we are only using an example in this case, let’s take a deeper look at how much time it can save in the process when we swap out a manual task with an automated task.
For example, it is very important to be able to quickly eliminate loan requests for unqualified candidates in a timely fashion. Using the manual task for risk evaluation, we might see something like the following process.
The applicant fills out the usual loan request form.
In our example, we were waiting for the risk verification task proactively, and it was picked up immediately.
We use the information gathered from our process with the financial information to obtain the proper loan risk for the applicant.

The following screenshot shows the path of this process instance to a rejection email sent because the individual had a high credit risk.
The entire process from start to finish took 1 minute and 8 seconds (as mentioned, we were proactively waiting for the manual task to verify the risk).
Note: This does not take into account the time required to enter the initial form information by the applicant.

Contrast that time with running the process without human intervention.
The same path is taken, but there is no wait in the process for an individual, who can make errors, to verify the risk manually.
Note: This does not take into account the time required to enter the initial form information by the applicant.

This process took 3 seconds from start to finish.
As you can imagine, if your organization gets 2,000 requests daily for possible loans, then the total time with a manual process—in a best case scenario—is:
2000 requests * 1.13 minutes = 2,260 minutes or 37 hoursAlternatively, if you replaced the manual verification process with the call to our machine learning prediction model service task, this number is:
2000 requests * 0.13 minutes = 266 minutes or just under 4 ½ hoursYou can start to see the benefit for streamlining this process with an automated task. Moreover, this machine learning model can continue to fine-tune itself by feeding results from new applicants back into the test set for a more robust prediction model.
In addition to providing a more streamlined and accelerated process, you can achieve so many more benefits using Camunda’s composable architecture to replace or swap older, legacy components with automated or newer technology elements.
Additional benefits of composability
This looks much like the previous process with the manual step; however, there are many associated benefits when taking the automated approach.
End-to-end process visibility and efficiency
Achieving end-to-end visibility in your processes ensures alignment with business objectives, including KPIs and other performance metrics. Using our simple example in this blog, leveraging Camunda’s composable architecture and replacing manual tasks with technical solutions reduced the loan rejection processing time by over 85%.
Process auditability
End-to-end auditability is critical to ensuring processes are executed consistently and effectively. With the right tasks in place, you gain complete transparency from start to finish, enabling consistent execution across your organization.
Process governance and regulatory compliance
True end-to-end process orchestration and visibility are essential for effective process governance. This approach ensures processes are consistently managed, aligned with organizational objectives, and adaptable to evolving needs. It also provides the insights and accountability needed to execute, monitor, and improve processes while integrating new technologies seamlessly.
By implementing a composable architecture, organizations can easily audit processes for regulatory compliance and assess the impact of modifications. Change management, including documentation, compliance tracking, and performance monitoring, becomes more efficient and manageable.
Take advantage of Camunda’s composable architecture in your processes
With a truly composable architecture, you can reduce your risk while improving accuracy, efficiency, and compliance. If you want to obtain more information about the benefits of composability, please see our Composability for Best in Class Process Orchestration blog.
Start the discussion at forum.camunda.io